
When was the last time you hand-wrote a loop without waiting for autocomplete? Or debugged an error without first pleading with an AI to figure it out?
These engines have devoured every Stack Overflow answer and GitHub commit they could find, then turned around and polished your functions, drafted your docs, and even suggested tests you never knew you needed.
LLMs (Large Language Models) are giant neural networks trained on massive collections of text and code. By predicting what comes next in a sequence of words or tokens, they can autocomplete your for-loops, spin up entire functions from a brief description, flag bugs you haven’t yet encountered, and even draft documentation you’ll never admit you didn’t write yourself.
Developers have embraced these models – 81% use them to write docs, 80% for testing, and 76% for coding itself.
In other words, more than three-quarters of your peers are already outsourcing their day-job chores to machines that never sleep, never complain, and occasionally hallucinate JavaScript errors.
So the real question isn’t whether you’ll use an LLM, it’s whether you can resist leaning on one.
LLMs Are Everywhere, Especially in Insurance
Large Language Models aren’t just making developers faster; they’re quietly transforming dozens of industries. From drafting legal contracts to generating product descriptions, these AI tools are showing up everywhere we write, reason, or repeat ourselves.
In insurance, their impact is particularly striking. Here’s how LLMs are already helping insurers and policyholders alike:
- Faster claims processing – Analyze damage reports, verify coverage, and summarize documents in seconds.
- Fraud detection – Spot suspicious claims with pattern recognition far beyond human reach.
- Customer support – Power chatbots that actually understand policy questions and escalate only when needed.
- Underwriting – Sift through medical history, income data, and risk profiles to recommend pricing tiers.
- Policy generation – Draft readable, customized policy documents based on input parameters.
- Regulatory compliance – Flag clauses that violate local laws or fall out of standard language.
- Sales support – Generate pitch decks or respond to RFPs with policy highlights pulled from dense PDFs.
- Renewal analysis – Analyze previous customer behavior and suggest smarter cross-sells or upgrades.
- Market research – Summarize competitor policies, rate trends, and customer reviews automatically.
- Internal training – Generate onboarding materials or simulate policy scenarios for new agents.
If you’re wondering what LLMs can actually do for regular people, not just developers, BeatMyInsurance is a great place to start.
Why Tokens and Context Windows Matter
What Is a Token?
A token is a chunk of text that the model “reads” at once. It can be as small as part of a word or as large as a short word. In practice, you can think of it this way:
- 1 000 tokens = 750 English words
Why Context Window Size Matters
Every model has a maximum number of tokens it can “keep in mind” when you send it a prompt. If you exceed that limit, it simply stops reading the rest. This affects how much code, documentation, or conversation you can feed it in one go.
How Big Are the Windows?
Here is a quick overview of token limits for popular coding models:
- 200 000 tokens
Models like Claude Opus 4 can handle around 150 000 words. That covers multi-file modules, large docs, or even a short novel. - 64 000 tokens
Models such as Claude Sonnet 4, DeepSeek R1/V3 can juggle about 48 000 words. Perfect for step-by-step refactoring or medium-sized services. - 16,000 tokens
Open models like DeepSeek Coder and IBM Granite Code manage roughly 12,000 words. Good for single files or a couple of helper modules. - 8 000 tokens
Lightweight options (CodeGemma, StarCoder, aiXcoder-7B) work on about 6 000 words. Ideal for focused functions or single-file completions. - 1 000 000 tokens
Giants like Gemini 2.5 Pro and GPT-4.1 give you up to 750 000 words in one shot. You can feed them entire codebases or sprawling documentation.
Choosing the Right Size
- If you need to analyze or refactor an entire service or library in one go, pick a model with a huge window.
- For quick snippets, demos, or small modules, a smaller-window open-source model might be faster and cheaper.
- When you hit the limit, break your work into files or logical sections and feed them in sequence.
With tokens and context windows clear in your mind, you’re ready to compare the best LLM for coding in 2025. Let’s get started!
Top 10 best LLMs for coding in 2025
Here are ten of the most capable code-focused LLMs in 2025, with brief notes on their strengths and limitations:
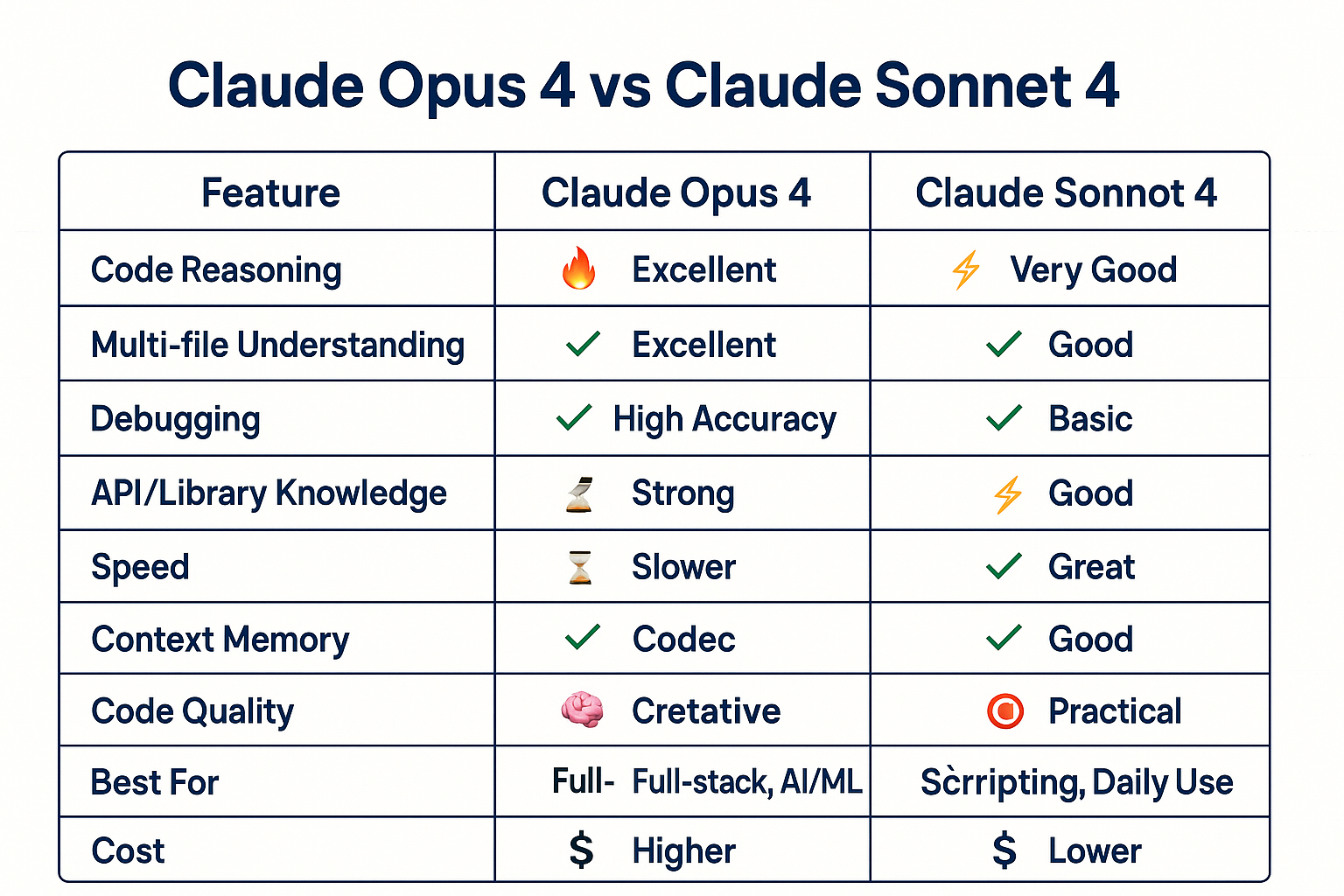
1. Claude Opus 4 (Anthropic)
Claude Opus 4 is designed for in-depth reasoning and complex projects. It excels at multi-step coding tasks such as large-scale refactoring or complex bug hunts.
Context Capacity
It can process up to 200,000 tokens in one go (about 150,000 words). This lets you feed in entire modules or several files without breaking them up.
Performance
On coding benchmarks, it leads peers. For example, it tops the SWE-bench leaderboard and scores very high on command-line and debugging tests.
Modes
You can choose a fast “standard” mode for quick replies or an “extended thinking” mode that devotes more computing power to step-by-step solutions.
Limitations
• Cloud only – no local install option
• Can be costly at scale (input and output token fees apply)
• Longer prompts and safety checks add some latency
Best Use Tips
• Break extremely large codebases into logical sections even with its large window
• Use standard mode for small tasks and switch to extended mode for deep work
• Cache repeated prompts and batch requests to reduce cost
• Always review, test, and security-scan generated code before using it in production
Claude Opus 4 Pricing
- Input tokens: $15 per 1 million tokens Anthropic
- Output tokens: $75 per 1 million tokens Anthropic
- Prompt caching (5 min TTL): write $18.75 / M tokens, read $1.50 / M tokens (up to 90 % savings) Anthropic
- Batch processing (asynchronous): input $7.50 / M tokens, output $37.50 / M tokens (50 % discount) Anthropic
2. Claude Sonnet 4 (Anthropic)
Claude Sonnet 4 is another top Anthropic model optimized specifically for coding. It excels at “agentic coding,” meaning it can plan out an entire project, write code, debug errors, and refactor, all in one session.
Context Capacity
It can handle up to 64 000 tokens in a single prompt (roughly 48 000 words). This makes it well suited for multi-file projects or larger modules without chopping them into tiny pieces.
Performance
On coding benchmarks it scores near the top, especially on tasks that require chaining together multiple steps (for example, planning, implementation, and validation). It slightly trails Opus 4 on raw reasoning tests but wins on end-to-end coding workflows.
Modes
– Standard mode for quick code snippets and simple fixes
– Agentic mode where it breaks down a task into sub-steps and executes them in sequence
Limitations
– API-only service, no local or offline install option
– Proprietary cloud service, so you need Anthropic API access
– Costs apply per input/output token, making heavy use potentially expensive
Best Use Tips
– Use agentic mode for full project overhauls or multi-file refactors
– For quick edits or small snippets, stick to standard mode to save time and cost
– Break extremely large codebases into logical chunks even within its 64 K token limit
– Cache repeated prompts and batch related requests when possible
Claude Sonnet 4 Pricing
- Input tokens: $15 per 1 million tokens
- Output tokens: $75 per 1 million tokens
- Prompt caching (5 min TTL): write $18.75 /M tokens, read $1.50 /M tokens (up to 90 % savings)
- Batch processing (asynchronous): input $7.50 /M tokens, output $37.50 /M tokens (50 % discount)
3. Gemini 2.5 Pro (Google DeepMind)
Google’s flagship model excels at coding and handling complex prompts. Gemini 2.5 Pro combines advanced math and science reasoning with a massive context window and true multimodal input support.
Context Capacity
It can process up to 1 000 000 tokens in a single prompt (about 750 000 words). This lets you feed in entire codebases, large datasets, or lengthy documentation without splitting them up.
Multimodal Inputs
• Code: Native support for multiple programming languages
• Images: Analyze or generate diagrams, UI mockups, and more
• Audio: Transcribe or reason over spoken instructions or code walkthroughs
Performance
Top performer on major coding benchmarks. It shines on tasks that mix code with diagrams or rich data, and its advanced reasoning helps solve algorithmic problems, complex refactors, and scientific computations.
Modes
• Standard mode for fast replies and simple code suggestions
• Deep reasoning mode (automatically invoked for complex prompts) to allocate extra compute toward step-by-step problem solving
Limitations
• Cloud only: Available via Google Cloud Vertex AI or Google’s API—no local deployment
• Latency: Its size can introduce slower response times compared to smaller models
• Cost: Larger compute requirements can mean higher per-token fees for heavy usage
Best Use Tips
• Reserve multimodal features (images, audio) for tasks that truly benefit from them
• Use standard mode for everyday code completion; lean on deep reasoning when tackling algorithms or multi-file refactors
• Chunk extremely large projects into logical units to avoid occasional timeouts
• Monitor latency and cost, batch related requests and cache prompts where possible to optimize spend.
Gemini 2.5 Pro Pricing
- Input tokens: $1.25 per 1 million tokens for prompts up to 200 K tokens; $2.50 per 1 million tokens for prompts over 200 K tokens
- Output tokens (including “thinking”): $10.00 per 1 million tokens for responses up to 200 K tokens; $15.00 per 1 million tokens for responses over 200 K tokens
- Context caching: $0.31 per 1 million tokens for cached prompts up to 200 K tokens; $0.625 per 1 million tokens for cached prompts over 200 K tokens
- Storage (context “holding”): $4.50 per 1 million tokens-hour for keeping cached context available
4. OpenAI GPT-4.1 (and Variants)
GPT-4.1 is OpenAI’s top model for coding today. It scores 54.6% on the SWE-bench, making it a leader for writing and fixing code. It can hold up to 1,000,000 tokens in its “memory,” so you can feed in large chunks of code or docs in one go.
Context Capacity
It handles up to 1,000,000 tokens (about 750,000 words) in a single prompt. That means you can work on big files or whole modules without chopping them up.
Performance
GPT-4.1 shows big gains in code generation and following instructions compared to earlier GPT models. It nails tricky edge cases, writes clearer comments, and fixes bugs more reliably.
Variants
- GPT-4.1 Mini: Smaller, cheaper, still solid for everyday code snippets.
- GPT-4.1 Nano: Fastest and lowest cost—great for quick suggestions or small edits.
Modes
You use it the same way you’d use other OpenAI models, via the ChatGPT UI or the API. Behind the scenes, it automatically shifts resources to match your request (no manual mode switch needed).
Limitations
• Cloud only, no local install option
• Paid API service, you send code to OpenAI’s servers
• Bigger context and deeper reasoning can add a bit of delay
Best Use Tips
• Use Mini or Nano for quick completions or when you need low latency
• Stick with full GPT-4.1 for complex, multi-file refactors or detailed bug hunts
• Cache repeated prompts to save on tokens
• Always review, test, and security-scan the AI’s output before you merge it
GPT-4.1 Pricing
- Input tokens: $30 per 1 000 000 tokens
- Output tokens: $60 per 1 000 000 tokens
- GPT-4.1 Mini: roughly $15 per 1 000 000 input / $30 per 1 000 000 output
- GPT-4.1 Nano: roughly $7.50 per 1 000 000 input / $15 per 1 000 000 output
5. DeepSeek R1 / V3
DeepSeek offers two flavors for different needs: DeepThink (R1) and Chat mode (V3).
What They Do
- R1 (DeepThink) uses chain-of-thought reasoning. It works through problems step by step, even if it takes minutes. Great for tough logic puzzles or multi-step coding tasks.
- V3 (Chat mode) is the everyday, fast-response model. It uses a Mixture-of-Experts design to be quick and cover almost any subject, perfect for general code completion or conversation.
Context Capacity
Both R1 and V3 can handle up to 64,000 tokens (about 48,000 words) in one prompt. You can drop in several files or large modules without slicing them up.
Performance
- R1 often outperforms older models like GPT-3.5 on complex logic and deep coding challenges.
- V3 is on par with other fast chat models, giving snappy, coherent code snippets and explanations.
Modes
- R1 / DeepThink: Slow, deliberate reasoning. Use it when you need the model to “show its work.”
- V3 / Chat: Instant responses. Use it for quick edits, brainstorming, or day-to-day coding help.
Limitations
- R1 can pause for minutes while it works through steps, no good for quick fixes. It’s also notably more expensive.
- V3 is speedy but may hallucinate on tougher logic or edge-case bugs.
- Neither mode offers a local install, they both run via DeepSeek’s cloud API.
Best Use Tips
- Pick V3 for everyday coding and interactive chats.
- Switch to R1 when you hit a tricky algorithm or multi-file refactoring that needs a clear reasoning trail.
- Even with 64 K tokens, break very large projects into logical sections (for example, per service or module) to keep things manageable.
- Cache repeated prompts and batch-related calls to save on time and cost.
DeepSeek Pricing (approximate)
- V3 Chat mode: $20 per 1 000 000 tokens
- R1 DeepThink mode: $60 per 1 000 000 tokens (about 3× the V3 rate)
6. DeepSeek Coder
A family of open-source models built just for code. Sizes range from about 1 billion to 33 billion parameters. They were trained on 2 trillion tokens (87 percent code) and use a 16,000-token window.
Context Capacity
They can handle up to 16,000 tokens in one prompt (around 12,000 words). That covers most single files or a couple of small modules at once.
Performance
State of the art among open-source code models. For example, DeepSeek-Coder-Base-33B beats CodeLlama-34B on Python benchmarks. Even the 7 billion-parameter version matches CodeLlama-34B on many tasks.
Strengths
• Free to use and run locally on your own hardware
• Excellent at Python completion and supports many other languages
• No API keys or cloud dependency, good for private or sensitive code
Limitations
• New release, so it may lack some polish around tool usage or instruction tuning
• Base models are decoder-only, you may want to use the “Instruct-33B” version for better out-of-the-box prompts
• Larger sizes require substantial RAM and GPU power
Best Use Tips
• Pick the smallest model that fits your hardware for quick tests, then move up if you need more accuracy
• Try the Instruct-tuned version if you want better prompt following without extra setup
• Fine-tune on your own codebase or use LoRA adapters for custom style and conventions
• Break very large projects into per-file or per-module prompts to stay within the 16 K window
Pricing
Free. No per-token fees. You only pay for your own computer when you run it locally.
7. IBM Granite Code
IBM’s open-source family of code LLMs, offered in Base and Instruct flavors at 3 B, 8 B, 20 B, and 34 B parameters. Designed with enterprise users in mind, Granite models are built on code from 116 programming languages.
Context Window
Up to 16,000 tokens (about 12,000 words). You can drop in a moderate-sized file or a handful of small modules without splitting them up.
What It Excels At
- Commercial-grade reliability: Clear licensing makes it safe for business use.
- Versatile tasks: From generating new code to explaining snippets, fixing bugs, or translating between languages.
- Polyglot strength: Handles 116 languages, so mixed-language repositories pose no problem.
- Research-backed: Backed by IBM’s WatsonX ecosystem and detailed documentation on GitHub.
Where It’s Less Ideal
- Smaller scale: Tops out at 34 B parameters, so it can fall behind the biggest commercial LLMs on very deep reasoning jobs.
- Resource needs: Running the larger models locally calls for hefty GPU/CPU power or using WatsonX.
- Prompt finesse: The Base editions may need extra prompt engineering; the Instruct editions smooth that out but still benefit from clear instructions.
Tips for Best Results
- Pick the right size: Start with 8 B or 20 B. Instruct for a sweet spot of speed and smarts.
- Mix and match: Use Base if you plan to fine-tune, or stick to Instruct for plug-and-play prompt following.
- Stay within limits: Chunk big codebases into files or packages to fit the 16 K token cap.
- Leverage IBM’s guides: Check out the examples and best practices on the Granite Code GitHub repo.
Cost
Free to download and run. Your investment is in the hardware or WatsonX credits you allocate for inference.
8. CodeGemma (Google)
CodeGemma is Google’s open-access family of code models built on the Gemma checkpoints. It comes in 2 B and 7 B parameter sizes, plus a 7 B “Instruct” version tuned for following prompts.
Context Capacity
Up to 8 000 tokens (around 6 000 words). You can work on single files or a few small modules without splitting them up.
Strengths
- Lightweight and free: Easy to run locally or in the cloud without API fees
- Tuned for code and math: Excels at filling in missing code or solving small algorithmic problems
- Strong benchmarks: CodeGemma-7B outperforms most similar-sized open models on coding tests
Limitations
- 8 K token window: Enough for many tasks but you’ll need to chunk larger projects
- Smaller scale: Won’t match top commercial models (like GPT-4.1 or Gemini 2.5 Pro) on deep reasoning or multi-file refactors
- Setup required: You’ll need to install via Hugging Face or Google Cloud and manage dependencies yourself
Best Use Tips
- Use 2 B model for quick infilling or experiments on low-resource machines
- Use 7 B Instruct model for clearer prompt following and fewer manual tweaks
- Break bigger codebases into file-by-file prompts to stay within the 8 K limit
- Combine with lightweight tools (linters, formatters) to polish AI output
Pricing
Free to use. Your only cost is the compute power you provide when running the models locally or on your cloud setup.
9. StarCoder (BigCode / Hugging Face)
StarCoder is a 15 billion-parameter, open-source model trained on permissively licensed GitHub data and fine-tuned with 35 billion Python tokens. It’s battle-tested in real-world coding workflows and powers everything from IDE completions to custom “Tech Assistant” prompts.
Context Capacity
- Handles just over 8,000 tokens (6,000 words) in one go, so you can drop in several related files or deep call chains without slicing them up.
Strengths
- Python expert: Fine-tuned on a massive Python corpus, it nails idiomatic code patterns, docstrings, and test scaffolding.
- Multi-file chops: The 8 K window lets you work across modules—think helper functions plus their callers together.
- Community-driven: Actively maintained on Hugging Face, with IDE plugins and notebooks demonstrating real use cases.
Limitations
- Token ceiling: At roughly 8 K tokens, really large services or entire frameworks need to be split into pieces.
- Reasoning edge cases: Not built for heavy math proofs or multi-step algorithm design, the way some closed-source giants are.
- Road map relies on volunteers: Updates and feature work depend on the open-source community rather than a dedicated vendor.
Usage Advice
- Drop in an entire Python module plus its tests to get context-aware completions.
- Pair StarCoder with a type checker (mypy) and linter (flake8) to catch edge-case bugs.
- For very large codebases, chunk by package or service layer to stay within the token limit.
StarCoder Pricing
- Self-hosted: Free to download and run—your only cost is the compute (CPU/GPU) you supply.
- Hugging Face Inference API: Pay per use based on the plan you choose (e.g., their CPU and GPU endpoint rates), but there are no per-token model fees.
10. aiXcoder-7B
A nimble 7 billion-parameter model built for razor-sharp code completion. Trained on 1.2 trillion code tokens with a “Structured Fill-In-the-Middle” objective, it often outperforms larger peers like StarCoder2-15B or CodeLlama-34B on real-world coding benchmarks.
Context Capacity
Not officially disclosed, but it likely handles around 8 000 tokens (a few thousand lines of code) in a single prompt.
Strengths
- Efficiency: Small footprint with enterprise-grade accuracy on code tasks.
- Accuracy: Beats several larger models on Python and multi-language completion tests.
- Open & Local: Run it on your own hardware for full data privacy and no API lock-in.
Limitations
- New release: Less community testing and ecosystem support than longer-lived models.
- Unknown context: May need experimentation to find its true window size.
- Setup work: Requires manual installation (e.g., via Hugging Face) and hardware with enough RAM.
Best Use Tips
- Start with small, single-file prompts and gauge how much context it ingests.
- Combine with code linters and formatters to catch any edge-case glitches.
- Fine-tune or use LoRA adapters if you need custom style consistency.
Pricing
- Self-hosted: Free to download and run—your only expense is the compute (CPU/GPU) you allocate.
- Cloud hosting: If you use a third-party inference service, you’ll pay their per-hour or per-call rates, but there are no model-specific token fees.
Comparison Of Top Models
This table will help choose the best LLM for coding in 2025:
| Model | Strengths | Considerations |
| Claude Opus 4 | • Best for deep reasoning and multi-step coding • 200 K-token window | • Cloud-only via Anthropic API • Can get pricey |
| Claude Sonnet 4 | • “Agentic” coding: plans, writes, debugs, refactors end-to-end • 64 K-token window | • Cloud-only • Higher cost for long sessions |
| Gemini 2.5 Pro | • Top Google model for code/math • 1 M-token window • Handles code, images, audio | • Only on Google Cloud/API • Higher latency/cost |
| GPT-4.1 | • Leader on coding benchmarks (54.6% SWE-bench) • 1 M-token window • Variants for speed/cost | • Paid API only • No offline use |
| DeepSeek R1 | • Chain-of-thought “DeepThink” mode for tough logic • 64 K-token window | • Very slow (minutes) • Most expensive mode |
| DeepSeek V3 | • Fast, fluent chat and code completion • 64 K-token window | • May hallucinate on hard logic |
| DeepSeek Coder | • Open-source (1–33 B params) • 16 K-token window • Beats most open models | • Needs local compute • Decoder-only base models |
| IBM Granite | • Commercial-friendly Apache 2 license • 3–34 B params • 16 K-token window | • Max 34 B params lags top closed models • Infra setup needed |
| CodeGemma | • Google’s open family (2 B & 7 B) • Strong code infill and math performance | • 8 K-token window • Smaller scale |
| StarCoder | • 15 B params • Kaggle-style Python expert • ~8 K-token window | • No multimodal support • Community-driven updates |
| aiXcoder-7B | • 7 B params but rivals much larger models • Efficient and accurate code completion | • New and less battle-tested • Unknown token limit |
Each of these models has trade-offs.
- For giant refactors or research code, try Claude Opus 4 or Gemini 2.5 Pro.
- For agent-style end-to-end workflows, use Claude Sonnet 4.
- For fast, everyday coding help, lean on GPT-4.1 Nano/Mini or DeepSeek V3.
- If you need a free, local option, spin up DeepSeek Coder, IBM Granite, CodeGemma, StarCoder, or aiXcoder-7B.
Looking to go deeper? Mockcertified provides free, exam-style practice tests for AWS, PMP, and more, perfect for devs and tech pros leveling up in cloud, project management, and beyond.
Beginner Mistakes When Using AI Coding Helpers
- Vague Prompts
If you ask a tool for “some code,” you might get useless answers. Always say exactly what you need: which programming language, what inputs and outputs you expect, and any examples or steps you have in mind. - Trusting AI Too Much
AI can look confident but still be wrong. Treat its code like a draft. Read every line, run tests, and fix errors yourself before using it in your project. - Sharing Sensitive Information
Pasting private or secret code into an online service can leak passwords or business logic. If your code is confidential, use a tool on your own computer or remove any secret data first. - Overloading the AI’s Memory
AI tools can only handle so much text at once. If you try to feed in thousands of lines of code, it will chop off the rest or fail. Break your work into small pieces or choose a model that can read more at once. - Thinking AI Replaces Learning
AI is like a helpful assistant, not a magic compiler. It will not teach you fundamentals or catch every mistake. Keep studying programming basics and use AI to speed up simple tasks or find ideas. - Ignoring License Risks
AI might copy code from somewhere without proper permission. Before you add any generated code to your project, make sure it does not violate any copyright or open-source license.
Common Questions About AI Coding Helpers
You may see these questions on beginner forums. Below each question, you’ll find a short answer in everyday terms.
- Which AI tool is best for writing code?
- There is no single best tool. Some are better at finishing small pieces of code. Others are stronger at finding and fixing complex errors.
- Think of it like choosing between a pencil and a pen. One might work better for quick notes. The other might be better for detailed work.
- Are there free AI tools that work as well as paid ones?
- Paid services (for example OpenAI or Google) often run faster and give more reliable answers. They are like a paid tutor.
- Free or open-source tools let you experiment without cost. They can be very good but may need more setup and might be slower.
- Can I trust these AI tools with my code?
- Privacy: If you send your private code online, check the service’s rules. Many now promise not to keep or learn from your code.
- Security: Never paste secret keys or passwords into an AI prompt. Treat the tool like a smart assistant, not a secure vault.
- Accuracy: AI can sometimes give wrong or made-up answers. Always check and test the code it gives you before using it.
- How much of my project can the AI tool read at once?
- AI tools have a limit on how much text they can process at one time. Older tools might handle around 6,000 words. Newer ones can handle 100,000 or more words.
- If your project is larger than the limit, break it into smaller parts (for example, one file at a time).
- How do I add AI help to my coding routine?
- Many code editors (for example, Visual Studio Code or JetBrains) have add-ons that show AI suggestions right where you type.
- You can also use chat-style tools on the web or in apps like Slack.
- If you prefer, you can run some AI tools on your own computer. This can give you more control but may require technical setup.
- Pick one tool at a time and learn how it works before trying another.
- Keep your secret keys and passwords out of AI prompts.
- Treat AI suggestions like advice from a helpful colleague. Always test the results.
- Break large code projects into small pieces so the AI can handle them.
With these basics, anyone can start using AI to make coding faster and easier. Good luck!
How to choose and use an LLM for coding (step-by-step)
- Identify your needs: What languages and tasks do you have? If you do lots of Python or web dev, pick a model trained heavily on those. If you need very long context (big data projects), look for models like Claude or Gemini.
- Decide open vs. cloud: If privacy or cost is a concern, try open-source models (StarCoder, CodeGemma, Granite Code) that you can run locally. If you want convenience and top performance, cloud models (ChatGPT, Claude, Gemini) might be worth it.
- Try free options first: Experiment with free tiers or demos. For example, Hugging Face Spaces has StarCoder or CodeGemma demos; Google Colab notebooks can run CodeGemma. OpenAI and Anthropic often have trial accounts.
- Test small projects: Before committing, compare a couple of models on a simple coding task. See which gives better code suggestions or understanding. Check their answers for accuracy.
- Learn prompt crafting: Good prompts make a big difference. Specify the language, ask for step-by-step answers, and include examples. For debugging, paste the error message and code snippet together.
- Integrate into your workflow: Use IDE extensions or APIs. For example, GitHub Copilot uses OpenAI models directly in VS Code. Anthropic Claude apps or Google Colab can link to Gemini.
- Vet and iterate: Always review the model’s output. Run the generated code to see if it works. Ask follow-up questions to refine code (e.g. “optimize this function”).
- Manage context: If the model forgets earlier parts of code, give it reminders. Some tools let you upload documents or use “memory” features. Break large problems into smaller steps (ask it one function at a time, etc.).
- Stay updated: The AI field moves fast. Check tech news or forums periodically for new models or upgrades (for example, GPT-4.1 and Claude 4 were released in 2025). The best LLM for coding last year might be surpassed soon.
- Combine tools wisely: Sometimes a small model (GPT-4.1 Mini, StarCoder) for quick completions plus a big model (Gemini) for planning is a good combo. Use what each model does best.
Frequently Asked Questions
Q: Are there any free coding AI models that actually work?
A: Oh, absolutely. If you think “free” means “useless,” think again.
- StarCoder (15 B parameters) was basically raised on GitHub and can autocomplete code like a pro.
- CodeGemma has 2 B and 7 B versions—light on resources but still impressively sharp.
- DeepSeek Coder is open-source and often beats paid rivals on benchmarks.
Run them locally, zero API bills.
If you’re feeling lazy, you can even squeak out some free GPT-4 credits in ChatGPT, or beg your school or employer for access.
Q: How safe are these AI helpers with my secret sauce?
A: You’re sending code to someone else’s servers.
- Cloud services (OpenAI, Anthropic, Google) will see whatever you paste. Keep your private keys, passwords, and trade secrets locked up.
- If you run StarCoder, CodeGemma, DeepSeek, or Granite Code on your own machine, you’re the boss of privacy.
Check each provider’s fine print, and don’t treat these models like Fort Knox. Always review output before you trust it with your precious IP.
Q: Can an AI model manage my massive, never-ending project?
A: AI has “memory” limits, so it will promptly forget your earlier files once you exceed its token budget.
- Chop your codebase into bite-sized pieces (files, modules, features).
- Use big-window models (Gemini’s one-million tokens or Claude’s 200 K) for bird’s-eye views.
- Consider orchestration tools like LangChain or agent frameworks to juggle multiple steps.
But don’t expect it to wake up tomorrow and finish your entire app on its own. It’s still your sidekick, not a replacement for you.
Q: What are “agentic” coding tools? Should I bother?
A: Agentic tools are the AI overachievers; they’ll run code, search docs, even call APIs without you clicking too much. Think GitHub Copilot Chat or Replit’s Ghostwriter taking initiative.
- Pros: They can fix bugs across files, fetch missing imports, or spin up tests automatically.
- Cons: They can also make unwanted changes, introduce weird bugs, and generally act like an overeager intern.
If you’re new, stick to simple chat with ChatGPT or Claude. Once you’ve earned some grey hairs, you can let the agents loose—just keep your review goggles on.
Q: How do I pick the “best” AI model for coding?
A: There is no magic wand. It depends on your vibe:
- Brute force power: GPT-4.1 or Gemini 2.5 Pro.
- Tight budget or offline play: StarCoder or DeepSeek Coder.
- Big refactors: Claude Opus 4.
- Quick hacks: GPT-4.1 Mini or DeepSeek V3.
Read the latest benchmarks (yes, that means actually clicking links), try a couple on your real tasks, and see which one doesn’t drive you up the wall. The best model is the one that saves you time, not your sanity.
Conclusion
Let’s wrap this up before your browser tab count hits double digits:
- Don’t depend on LLMs entirely. They help you write, refactor, and debug, but they won’t replace your caffeine-fueled late-night coding sessions.
- Be crystal clear. Vague prompts lead to “meh” answers. Spell out your language, inputs, outputs, and any examples you have in mind.
- Always double-check. Treat AI output like code from that one intern who means well but sometimes invents functions out of thin air. Read it, test it, lint it, and security-scan it before merging.
- Play to each model’s strengths. Need a bird’s-eye view of your entire repo? Reach for Claude Opus 4 or Gemini 2.5 Pro. On a shoestring budget or running locally? Fire up StarCoder or DeepSeek Coder.
- Respect the memory limits. Chunk big projects into files or modules so your chosen model doesn’t forget the first half of your code by the time it finishes the second.
- Guard your secrets. If you’re using a cloud service, keep API keys and proprietary logic out of prompts. For full privacy, host an open-source model yourself.
- Keep learning. LLMs speed up routine tasks but won’t teach you core algorithms or data structures. Use them to sharpen your workflow, not to dull your skills.